Big Data Management Exercises
Principle in Data Science Exercises
Data Analytics Exercises
Data Mining Exercises
Network Security Exercises
Other Exercises:
Python String Exercises
Python List Exercises
Python Library Exercises
Python Sets Exercises
Python Array Exercises
Python Condition Statement Exercises
Python Lambda Exercises
Python Function Exercises
Python File Input Output Exercises
Python Tkinter Exercises


Big Data Management - Exercises 1
1. Identify big data resource online.Ans: For this case, the dataset of bank details was search from Kaggle with 41188 rows and 21 attributes. This is useful for financial services.
2. Why the identified resource is considered big data?
Ans: This dataset is a portion of data from the bank. In fact if these data are accumulated for years it can be considered as big data. This bank data has 21 attributes such as age, marital status, educational level, etc. They consist of different types of data that are collected from banks. The variety of data can be divided into structured and unstructured data. The volume is defined as the size of data (B.M, 2018). As mentioned earlier, after the data has accumulated for years, then the volume of data is huge. Other than that, the velocity of bank data is growing fast too.
For instance, these data are collected in the Bank from India country. The population of India was estimated to be 1.3 billion. Let us assume that the 10% out of the total India population have updated their bank details such as personal details, loan status, etc. annually. These activities involve about 13 million of Indian, let alone this data has yet to include the foreigners who are currently residing in India due to working or studying. It is a huge volume of data generated annually with high speed in India banks database.
Furthermore, the veracity is another characteristic in bank data. It is about the accuracy and reliability of data. (B.M, 2018). The accuracy of data such as bank user profiles, bank account number, saving amount, etc. in banks are highly important. For instance, a bank user who has applied for a car loan to buy a new car with the bank, after the loan approval, the loan applicant shall conduct the repayment monthly. The repayment process can only be proceeded successfully with the veracity of data.
These big data in banks can also generate valuable insight to enhance revenue of the bank. This is the business value created by big data. The loan approval process can be shortened with the help of big data by generating out the predictive loan defaulter. This predictive tool can help bank workers to do the approval process to ensure the loan defaulter rate can be reduced further. The characteristics of big data have included variability by Gartner in 2012 (Gandomi & Haider, 2015). The variability is different from the variety of big data characteristics in the first place. Variability means the understanding and interpreting of data is constantly changing (Impact, 2019).
For instance, when bank customers review on their services with the following examples:
• Great bank services.
• Greatly disappointed with the bank services
The interpretation of these customer reviews might be changing constantly from positive to negative and back to positive review depending on the machine learning algorithms. Lastly, visualization is another characteristic of bank data to present the bank customers profile information, bank account information, loan amount etc. Better visualization can help customers to capture the information easily.
3. Why the identified resource is useful to your chosen sector?
Ans: The identified resource consists of information about customer profiles and loans taken by bank customers. Furthermore, the bank workers can find out the demographic information of customers financially able to take a bank deposit. After getting the information, the sales department of the bank can perform the customers targeting in their sales strategy to increase the bank revenue by increasing the qualified loan applicant and approved loan applicant.
4. Explain the most suitable method to store the big data resource.
Ans: A digital database based on the relational model is defined as a relational database. A software system named relational database management system (RDBMS) used to maintain relational databases. It is the same as the XML database and also a conventional database system. Hence, it is not the best choice to be selected for big data (Hammood and Saran, 2016). Besides, bank data can be generated daily so the data growing rate is very speedy therefore the bank data is huge and cannot be managed properly by using conventional types of database such as SQL database, relational database, etc.
Big data resources are more suitable on NoSQL database systems because it provides scalability in the horizontal direction. MongoDB and Hbase are one of the NoSQL databases. Currently, most of the NoSQL databases design are either simple or identical to object-oriented programming languages. There are a number of NoSQL databases in the market, different NoSQL database systems have their respective benefits. It is important to select the suitable database according to the datasets because the switching of databases can consume a lot of resources and time.
In terms of performance, MongoDB can perform well in small data sizes. However, Hbase is able to perform well in big data sizes. The population in India consists of 1.3 billion, assuming 10% of the population in India will be involved in bank activities such as car loan application, housing loan application, new bank account registration, bank transaction, etc. These activities can generate huge amounts of data in high velocity daily. Due to the characteristics of bank data in India, Hbase is more suitable to be used compared to MongoDB in order to achieve better performance.
Other than that, the core activity of a bank is bank transactions. The transaction speeds should be one of the main factors to select the most suitable databases. Hbase is able to obtain higher throughput compared to MongoDB. Meanwhile, Hbase is also able to achieve a latency increase after comparing with performance of MongoDB (Hammood and Saran, 2016). In conclusion, Hbase is the most suitable database to be used for the bank data.
5. Demonstrate the process to store the big data resource (from Question 1) using discussed method (from Question 4)
Ans: Firstly, a folder is created in the HDFS as a place to store the dataset. Then, the dataset is loaded into the specified folder as shown in the Figure below.
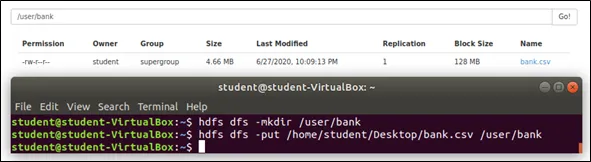
A Hbase table named bank_data_R2 is created as shown in the Figure below.

The column family named as cf. Figure below displays the process of loading a csv file from HDFS into HBase. Importtsv is a utility that can be used to help in this process.

6. Demonstrate a way to access the stored big data resource (from Question 5) and extract meaningful outcome for the chosen sector (from Question 1).
Ans: The code is shown in Figure below to access the bank data that has been stored into the HDFS. The displayed data has been limited to the first five rows for demonstration purposes.

After that, Figure below presented the codes to access the data from HBase table.
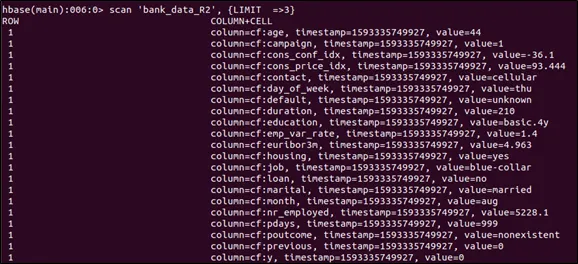
Figure below illustrated the codes to create a hive external table on top of Hbase table.
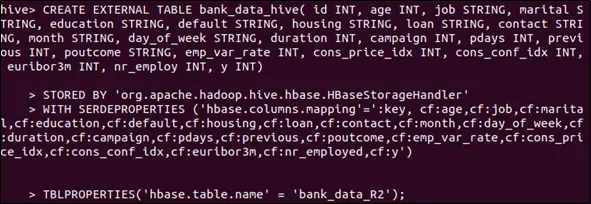
The aggregation will be carried out in the Hive. The data in a Hive external table also can be accessed and shown in Figure below.
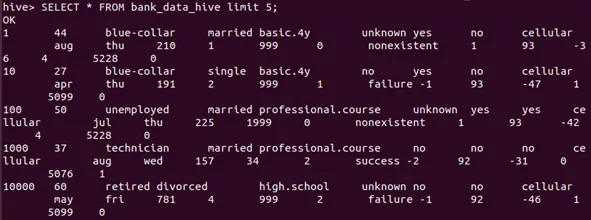
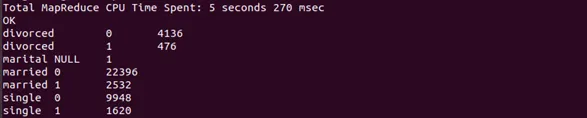
The meaningful information such as demographic information of customers financially able to take a bank deposit. Furthermore, Figure 8 shows the result that bank customers who are still single in marital status will tend to take a bank deposit compared to other marital status such as divorced and married.

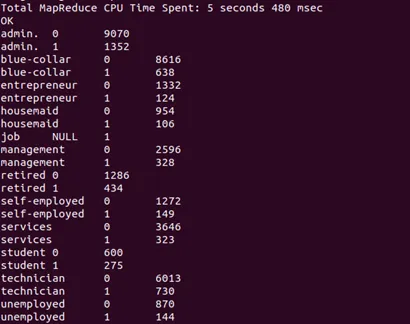
Next, a bank customer who is more willing to take a bank deposit can be seen from their occupation as displayed in Figure below.

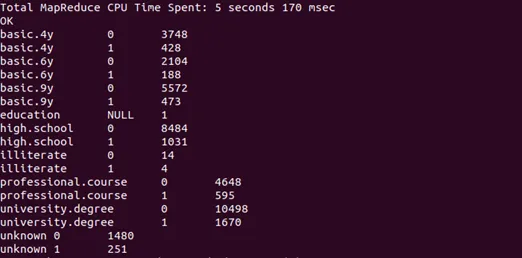
After that, Figure 10 presents the educational level of a customer who is more willing to take a bank deposit. Based on the results, the sales team from the bank can do customer targeting to enhance their sales further.

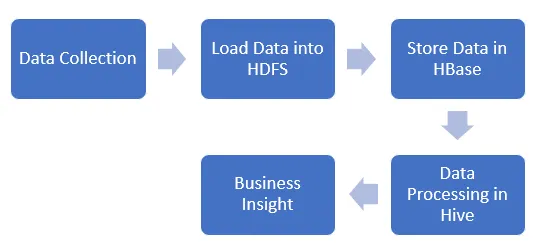
7. Draw a big data pipeline based on the discussion from Question 1 to Question 6.
Ans: The data is collected and loaded into HDFS. Then data is stored in the Hbase for updating the data at any time. The business insight of a bank can be gained after data processing in the Hive.
8. Consider the table of term frequencies for 3 documents denoted Doc1, Doc2, Doc3 in Table 1.0.
For each document, compute the tf-idf weights for the following terms using the idf values from Table 1.1.
• cat
• animal
• iguana
• bee
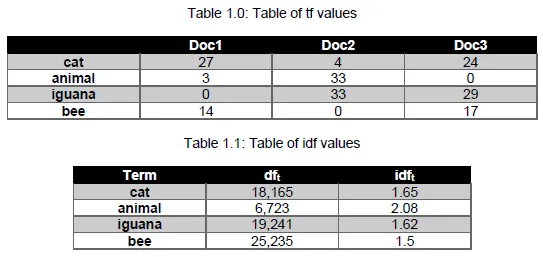
Ans:
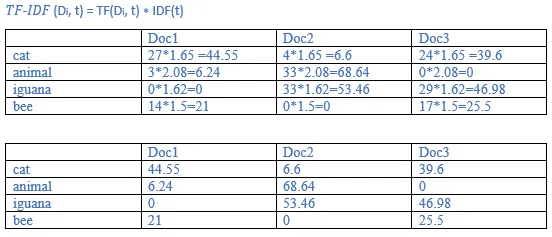
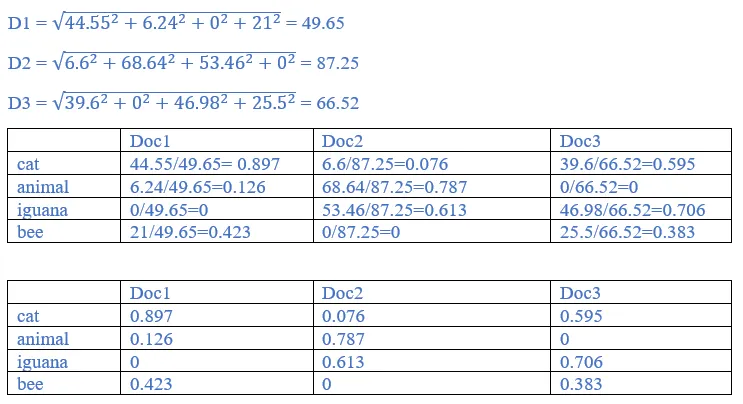
9. Recall the tf-idf weights computed previously. Compute the Euclidean normalized document vectors for each of the documents, where each vector has four components, one for each of the four terms.
Ans:
10. With term weights computed previously, rank the three documents by computing the score for the query “cat iguana”, based on each of the following cases of term weighting in the query:
a. The weight of a term is 1 if present in the query, 0 otherwise.
Ans:
Hence, query:
Cat : 1
Animal: 0
Iguana: 1
Bee: 0
Product= query * term weights from previous answer.
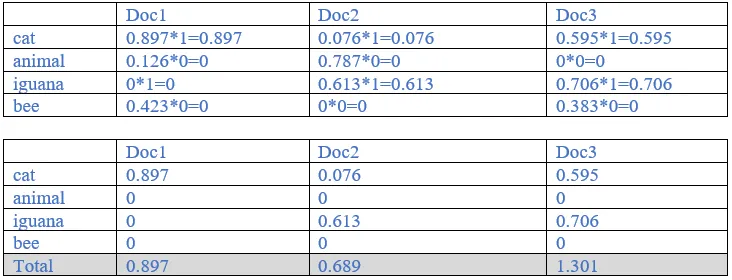
The three documents rank as: Doc3 (1.301) > Doc1(0.897)>Doc2(0.689)
b. Euclidean normalized idf.
Ans:
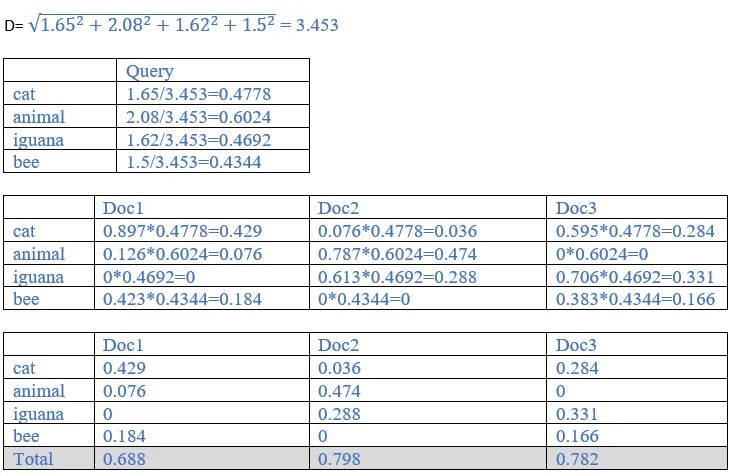
The three documents rank as: Doc2 (0.798) > Doc3(0.782)>Doc1(0.688)
11. Compute the PageRank of each page, assuming no taxation.
Ans:
You can put an assumption value for B.

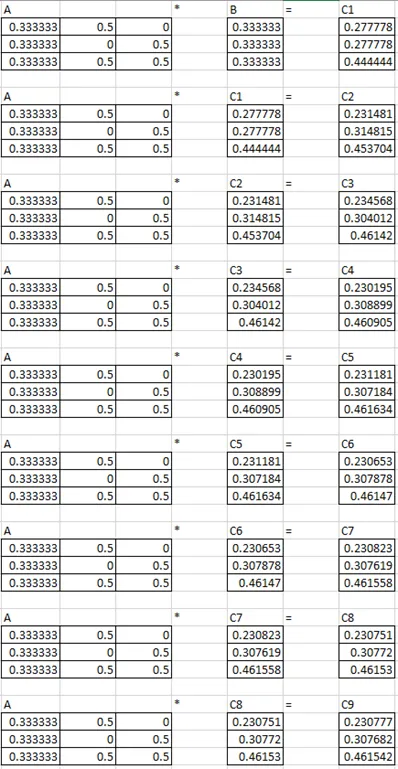
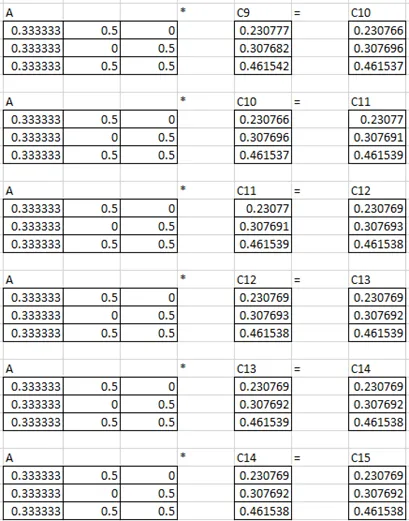
Pagerank of a:0.23077
Pagerank of b:0.30769
Pagerank of c:0.46154
12. Compute the PageRank of each page in Figure 1.0, assuming β = 0.8.

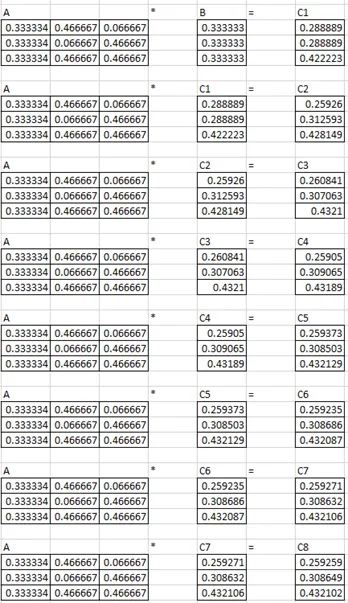
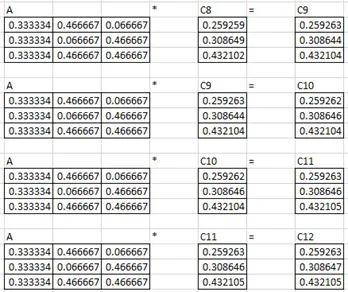
Pagerank of a:0.25926
Pagerank of b:0.30865
Pagerank of c:0.43211
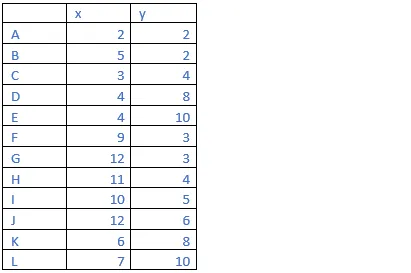
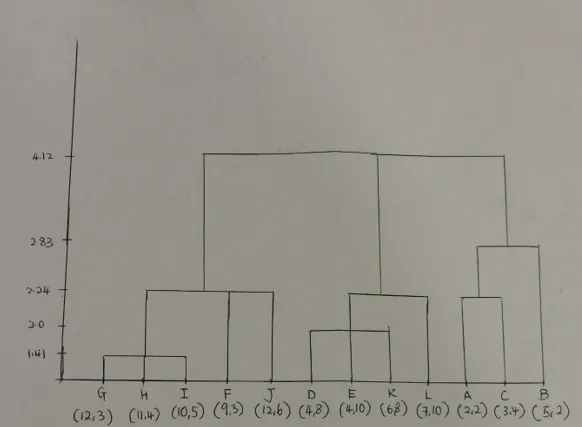
13. Figure below contains twelve points that live in 2-dimensional Euclidean space, and each of the point is named by its (x, y) coordinates. Perform hierarchical clustering of the points in Figure below.
The distance between two clusters is defined to be the minimum of the distances between any two points, one chosen from each cluster.
State clearly the steps that you have taken to merge the different clusters, along with the distance matrices.
State the result of the clustering using a tree representation or a dendrogram.
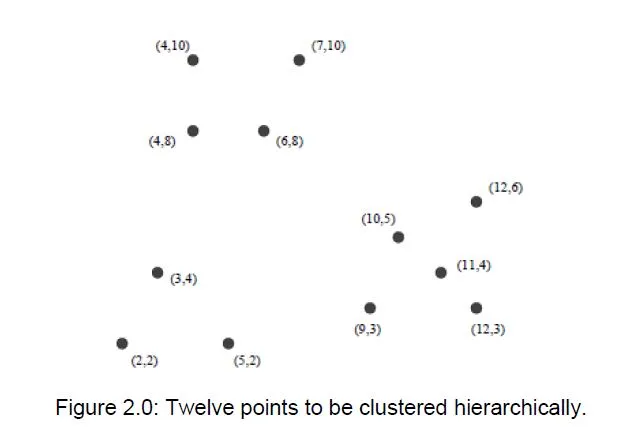
Ans:
Step 1:Using Euclidean distance to compute the distance matrix between points:
Euclidean Distance = sqrt( (x2 -x1)**2 + (y2-y1)**2 )
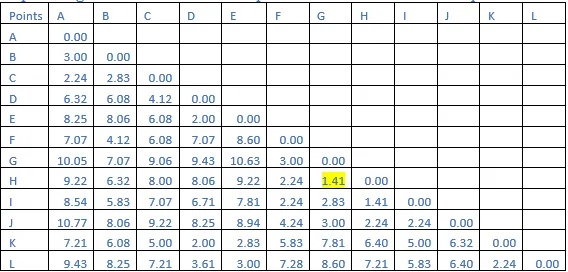
Step 2: The shortest distance in the matrix above is 1.41. So, the vector associated with that are G&H. Find the new distance in the following matrix.
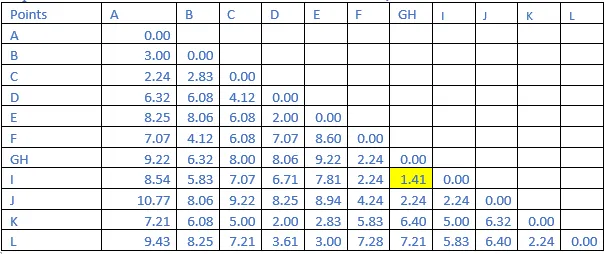
Step 3: The shortest distance in the matrix above is 1.41. So, the vector associated with that are GH&I. Find the new distance in the following matrix.
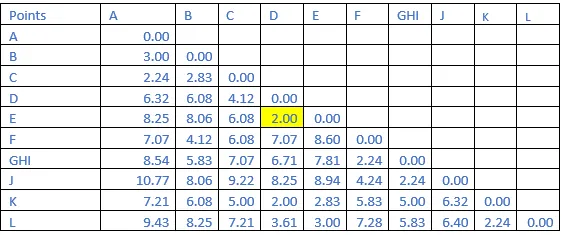
Step 4: The shortest distance in the matrix above is 2.00. So, the vector associated with that are D&E. Find the new distance in the following matrix.
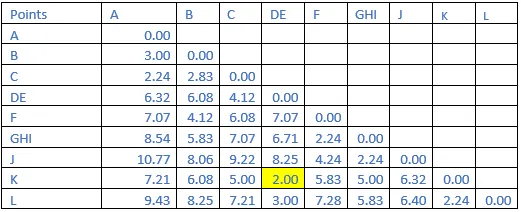
Step 5: The shortest distance in the matrix above is 2.00. So, the vector associated with that are DE&K. Find the new distance in the following matrix.
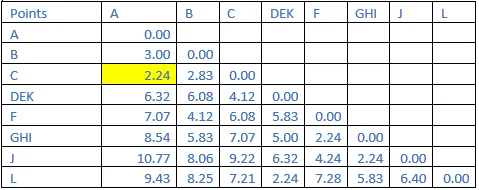
Step 6: The shortest distance in the matrix above is 2.24. So, the vector associated with that are A&C. Find the new distance in the following matrix.
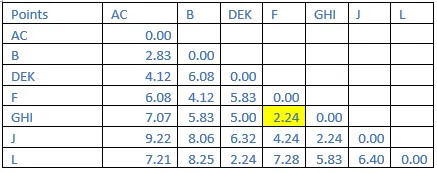
Step 7: The shortest distance in the matrix above is 2.24. So, the vector associated with that are F&GHI. Find the new distance in the following matrix.
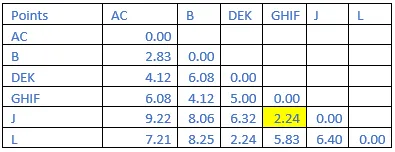
Step 8: The shortest distance in the matrix above is 2.24. So, the vector associated with that are GHIF&J. Find the new distance in the following matrix.
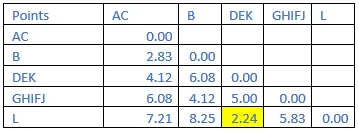
Step 9: The shortest distance in the matrix above is 2.24. So, the vector associated with that are DEK&L. Find the new distance in the following matrix.
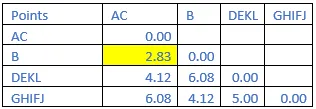
Step 10: The shortest distance in the matrix above is 2.83. So, the vector associated with that are AC&B. Find the new distance in the following matrix.
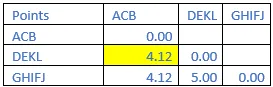
Step 11: The shortest distance in the matrix above is 4.12. So, the vector associated with that are ACB& DEKL. Then last the final cluster is shown.
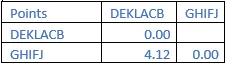
State the result of the clustering using a tree representation or a dendrogram
14. The goal of Support Vector Machine is to fine a hyperplane, i.e., a decision boundary that linearly separates the points into different classes.
Given the hyperplane defined by y = x1 - 2x2.
i. How do you find the projection of a point x , to the specified hyperplane?
Ans:
The projection of a point x onto a specified hyperplane w is based on xT w/|w|2.
ii. What are the distances of the following points from the hyperplane
• x =[−1,2]
Ans:

• x = [1, 0]
Ans:

• x = [1,1]
Ans:

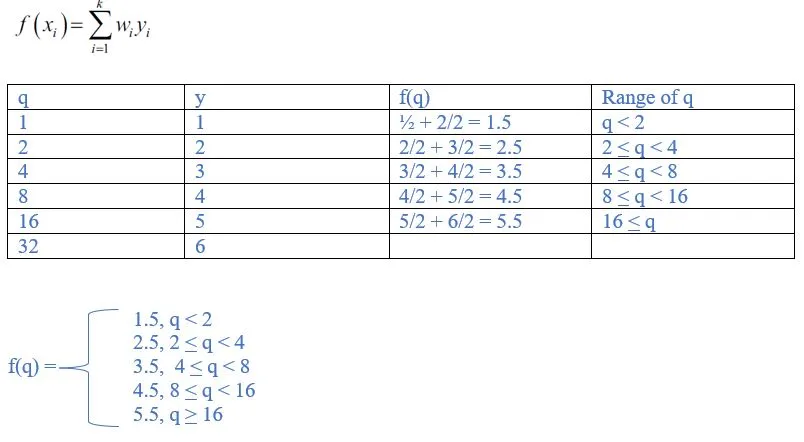
15. Consider the following one-dimensional training set
<1,1), (2,2), (4,3), (8,4), (16,5), (32,6)
Describe the function f(q), the label that is returned in response to the query q, when the interpolation used is:
(a) The label of the nearest neighbour
Ans:
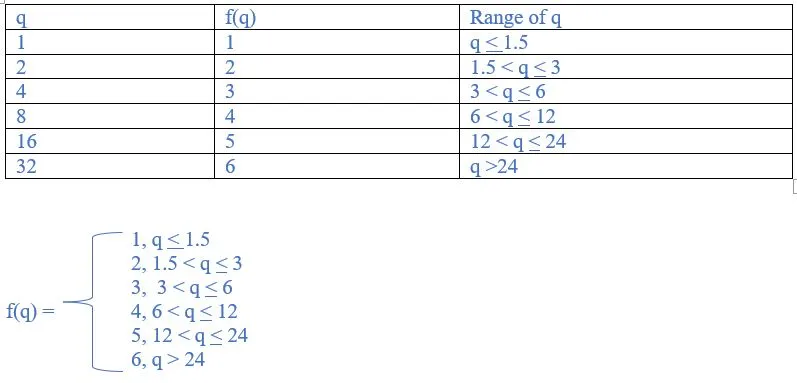
(b) The average of the labels of the two nearest neighbours
Ans:
In the case of this question, the value of k = 2 (because we are considering 2 nearest neighbors). And the weight, wi for each xi is therefore ½. Therefore, the formula above can be simplified as follows:
16. Compute the Jaccard similarities of each pair of the following three sets:
{1, 2, 3, 4}, {2, 3, 5, 7}, and {2, 4, 6}.
Ans:
J({1, 2, 3, 4}, {2, 3, 5, 7}) = 2/6 = 1/3
J({1, 2, 3, 4}, {2, 4, 6}) = 2/5
J({2, 3, 5, 7}, {2, 4, 6}) = 1/6
17. What are the first seven 3-shingles in the following sentence?
“The most effective way to represent documents as sets, for the purpose of identifying lexically similar documents is to construct from the document the set of short strings that appear within it.”
Ans:
“The most effective”, “most effective way”, “effective way to”, “way to represent”, “to represent documents”, “represent documents as”, “documents as sets”
18. What do you understand by “Big Data”, can you explain the term?
Ans:
Big data is a term that describes the specific data set which able to fulfil the Vs characteristics such as variety, volume, velocity, veracity, variability, visualization, etc. Variety is defined as different type of data in structured, semi-structured or unstructured format. Volume refers to the size of data. Velocity is the speed at which the data gets generated. Then veracity is about the accuracy of data. The variability is different from variety of big data characteristics in the first place. Variability means the understanding and interpreting of data is constantly changing. Visualization is presenting large amounts of complicated data.
19. Provide four of the V’s used to characterize Big Data, and explain them with suitable example for each V.
Ans:
Shopee data can be considered as Big data which fulfils at least four Vs characteristics such as variety, volume, velocity, and veracity. Shopee has variety of data which refer to the different kinds of data that are formed and stored in the database. The variety of data normally divided into two different categories such as structured data and unstructured data. For structured data, Shopee business generated a lot of data in the form of text such as sellers and users’ personal data, customer reviews, product details and so on. While as for unstructured data, it is generated in the form of video and images of selling products.
The volume refers to the size or amount of data and Shopee has huge volume of data. This is due to the Shopee has a lot of texts, videos, and images data from 7 million active sellers and more than 700 million app users which have highlighted in the previous paragraph. Basically, a text file size is about few kilobytes, whereas a JPEG image file is in range of few hundred kilobytes to few megabytes. Lastly, a three to four minutes of high definition video file is roughly one hundred megabytes. Assuming 700 million app users have updated their personal profiles, the data size of personal profiles itself can roughly achieve almost 1 Terabytes (700 million users multiply with estimated text file size), it has not yet included other data such as retail data, product consumption and etc.
The velocity means the speed at which the data gets generated and streamlined. For instances, the gross orders of Shopee has surged from 127.8 million in second quarter of 2018 to 246.3 million in the second quarter of 2019. It grows 92.7% compared to a year ago, this also help in growing the data such as retail transaction data, shipping data, customer profiles, product consumption and customer reviews with high velocity.
Next, the characteristics of big data in Shopee business is veracity. The veracity is about accuracy and reliability of data. The data in Shopee such as retail transaction data, shipping data, customer profiles, product data and seller profiles are accurate data. For instance, after customers have placed order and made payment to any of products in the Shopee, the customer profiles such as bank account details shall be accurate to ensure the transaction can be proceeded successfully. Therefore, shipping data of customers play important roles to make sure that the bought items can delivery according to the accurate address of customers. But if the product owners out of their house, the contact number of product owners are important to ensure shipper able to contact product owners to determine the second delivery date and time. Without veracity data, the whole retail process cannot be done successfully.
20a. Produce MapReduce algorithms (in the form of a pseudo-code) to take a very large file of integers and produce as output, the same set of integers, but with each integer appearing only once.
e.g., of a pseudocode design for the word count problem is as follows:
map(key, value):
//key: large file of integers; value: numbers in the document
for each number n in value:
emit(n, 1)
reduce(key, value):
//keys: a number; value: an iterator over counts
output_number = 0
result_count = 0
if output_number == number:
result_count += count
emit(output_number)
Ans:
Map: For each integer i in the file, emit key-value pair (i, 1)
map(key,value):
// key: file name, value: integers in the file
for each integer i in value:
emit (i,1)
Reduce: Turn the value list into 1.
reduce(key, value)
//key: an integer, value: an iterator over integers
current_integer = None
for each i in values:
if (current_integer == i)
#do nothing
else
current_integer = i
emit(i)
*This approach works because the keys are sorted prior to being passed to the reducerb.
i. Using the pseudocode designed in (a) and based on your knowledge of running Hadoop and MapReduce using Python, write a functional program to execute the task defined in (a) for the input file, “integer_data.txt”. The sample output is as provided in “sample_output.txt”.
You are to submit the followings for this question:
• hadoop_mapreduce.ipynb (which is your driver code for mapper and reducer)
• mapper.py (containing the map function)
• reducer.py (containing the reduce function)
• The text output of the task
Ans:
#mapper.py
import sys
import io
for line in input_stream:
line = line.strip()
integers=line.split()
for integer in integers:
print('%i\t%i' % (int(integer), 1))
#reducer.py
from operator import itemgetter
import sys
current_integer = None
current_count = 0
integer = None
#input comes from STDIN
for line in sys.stdin:
#remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
integer, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
#count was not a number, so silently
#ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: integer) before it is passed to the reducer
if current_integer == integer:
#do nothing
else:
if current_integer:
# write result to STDOUT
print ('%s' % (int(current_integer))) #emit the unique integer
current_count = count
current_integer = integer
# do not forget to output the last integer if needed!
if current_integer == integer:
print ('%s' % (int(current_integer))) #emit the unique integer
ii. Using suitable examples relevant for the previous task (i.e. task defined in (a)), explain how the MapReduce algorithm works. Specifically, detail out the following, different phases in MapReduce involved as follows with regards to the task defined in (a):
• Input splitting
• Mapping
• Shuffling
• Reducer
Ans:
Input Splits:
An input to a MapReduce job is divided into fixed-size pieces called input splits Input split is a chunk of the input that is consumed by a single map
Mapping
This is the very first phase in the execution of map-reduce program. In this phase data in each split is passed to a mapping function to produce output values. In our example, a job of mapping phase is to detect the occurrences of each integer from input splits, and prepare a list in the form of (integer, frequency).
Shuffling
This phase consumes the output of Mapping phase. Its task is to consolidate the relevant records from Mapping phase output. In our example, the same integers are clubbed together along with their respective frequency.
Reducing
In this phase, output values from the Shuffling phase are aggregated. This phase combines values from Shuffling phase and returns a single output value (i.e., the unique integer).
c. In a Hadoop Distributed File System (HDFS), there is a node known as NameNode.
Explain what a NameNode is, and explain the followings in relation to NameNode within a HDFS
• fsimage file & edits file
• Checkpoint NameNode
• Backup Node
When necessary, draw the diagram(s) depicting how NameNode relates to Checkpoint NameNode and the Backup Node.
Ans:
What is a NameNode?
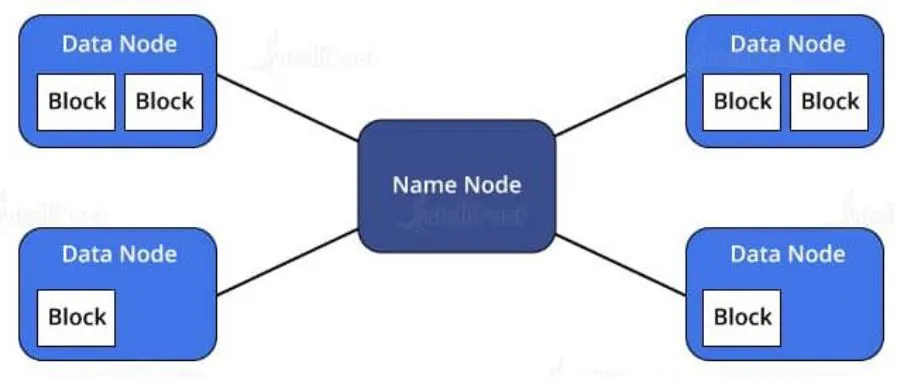
NameNode is the core of HDFS that manages the metadata—the information of which file maps to which block locations and which blocks are stored on which DataNode. In simple terms, it is the data about the data being stored. NameNode supports a directory tree-like structure consisting of all the files present in HDFS on a Hadoop cluster. It uses the following files for namespace:
• fsimage file: It keeps track of the latest Checkpoint of the namespace.
• edits file: It is a log of changes that have been made to the namespace since Checkpoint.
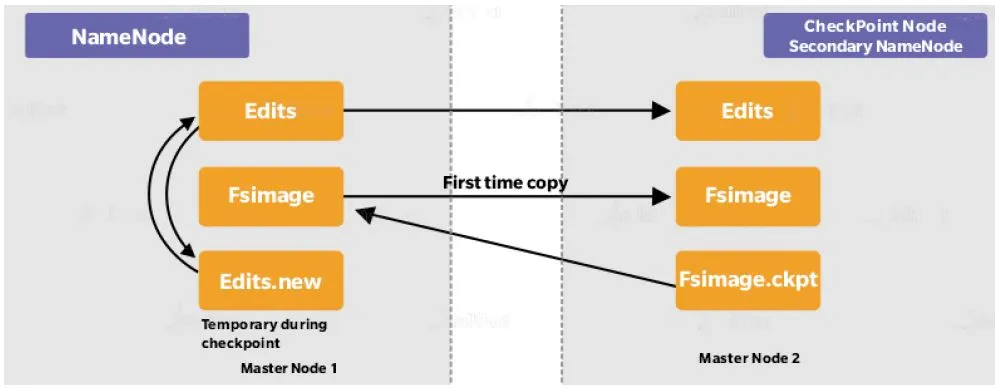
Checkpoint NameNode has the same directory structure as NameNode and creates Checkpoints for namespace at regular intervals by downloading the fsimage, editing files, and margining them within the local directory. The new image after merging is then uploaded to NameNode. There is a similar node like Checkpoint, commonly known as the Secondary Node, but it does not support the ‘upload to NameNode’ functionality.
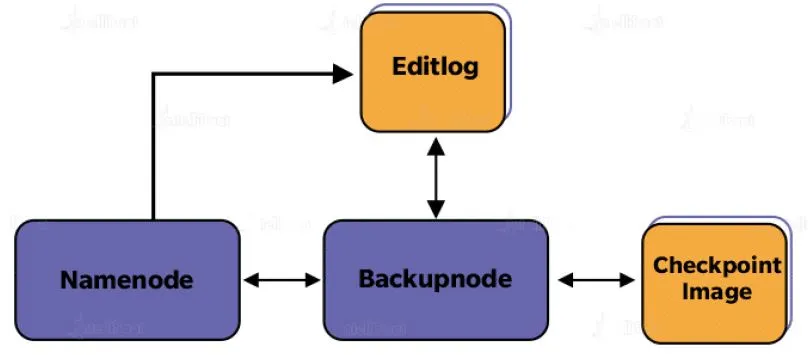
Backup Node provides similar functionality as Checkpoint, enforcing synchronization with NameNode. It maintains an up-to-date in-memory copy of the file system namespace and doesn’t require getting hold of changes after regular intervals. The Backup Node needs to save the current state in-memory to an image file to create a new Checkpoint.
More Free Exercises:
Data Science ExercisesBig Data Management Exercises
Principle in Data Science Exercises
Data Analytics Exercises
Data Mining Exercises
Network Security Exercises
Other Exercises:
Python String Exercises
Python List Exercises
Python Library Exercises
Python Sets Exercises
Python Array Exercises
Python Condition Statement Exercises
Python Lambda Exercises
Python Function Exercises
Python File Input Output Exercises
Python Tkinter Exercises